Diagonalizable matrix
In linear algebra, a square matrix A is called diagonalizable if it is similar to a diagonal matrix, i.e., if there exists an invertible matrix P such that P −1AP is a diagonal matrix. If V is a finite-dimensional vector space, then a linear map T : V → V is called diagonalizable if there exists a basis of V with respect to which T is represented by a diagonal matrix. Diagonalization is the process of finding a corresponding diagonal matrix for a diagonalizable matrix or linear map. [1] A square matrix which is not diagonalizable is called defective.
Diagonalizable matrices and maps are of interest because diagonal matrices are especially easy to handle: their eigenvalues and eigenvectors are known and one can raise a diagonal matrix to a power by simply raising the diagonal entries to that same power. Geometrically, a diagonalizable matrix is an inhomogeneous dilation (or anisotropic scaling) – it scales the space, as does a homogeneous dilation, but by a different factor in each direction, determined by the scale factors on each axis (diagonal entries).
Contents |
Characterisation
The fundamental fact about diagonalizable maps and matrices is expressed by the following:
- An n-by-n matrix A over the field F is diagonalizable if and only if the sum of the dimensions of its eigenspaces is equal to n, which is the case if and only if there exists a basis of Fn consisting of eigenvectors of A. If such a basis has been found, one can form the matrix P having these basis vectors as columns, and P−1AP will be a diagonal matrix. The diagonal entries of this matrix are the eigenvalues of A.
- A linear map T: V → V is diagonalizable if and only if the sum of the dimensions of its eigenspaces is equal to dim(V), which is the case if and only if there exists a basis of V consisting of eigenvectors of T. With respect to such a basis, T will be represented by a diagonal matrix. The diagonal entries of this matrix are the eigenvalues of T.
Another characterization: A matrix or linear map is diagonalizable over the field F if and only if its minimal polynomial is a product of distinct linear factors over F. (Put in another way, a matrix is diagonalizable if and only if all of its elementary divisors are linear.)
The following sufficient (but not necessary) condition is often useful.
- An n-by-n matrix A is diagonalizable over the field F if it has n distinct eigenvalues in F, i.e. if its characteristic polynomial has n distinct roots in F; however, the opposite may be false. Let us consider
-
- which has eigenvalues 1, 2, 2 (not all distinct) and is diagonalizable with diagonal form (also the similar matrix of A)
- and change of basis matrix P
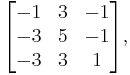

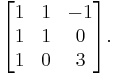
- A linear map T: V → V with n = dim(V) is diagonalizable if it has n distinct eigenvalues, i.e. if its characteristic polynomial has n distinct roots in F.
Let A be a matrix over F. If A is diagonalizable, then so is any power of it. Conversely, if A is invertible, F is algebraically closed, and An is diagonalizable for some n that is not an integer multiple of the characteristic of F, then A is diagonalizable. Proof: If 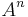 is diagonalizable, then A is annihilated by some polynomial
is diagonalizable, then A is annihilated by some polynomial  , which has no multiple root (since
, which has no multiple root (since 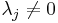 ) and is divided by the minimal polynomial of A.
) and is divided by the minimal polynomial of A.
As a rule of thumb, over C almost every matrix is diagonalizable. More precisely: the set of complex n-by-n matrices that are not diagonalizable over C, considered as a subset of Cn×n, has Lebesgue measure zero. One can also say that the diagonalizable matrices form a dense subset with respect to the Zariski topology: the complement lies inside the set where the discriminant of the characteristic polynomial vanishes, which is a hypersurface. From that follows also density in the usual (strong) topology given by a norm. The same is not true over R.
The Jordan–Chevalley decomposition expresses an operator as the sum of its semisimple (i.e., diagonalizable) part and its nilpotent part. Hence, a matrix is diagonalizable if and only if its nilpotent part is zero. Put in another way, a matrix is diagonalizable if each block in its Jordan form has no nilpotent part; i.e., one-by-one matrix.
Diagonalization
If a matrix A can be diagonalized, that is,
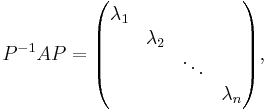
then:
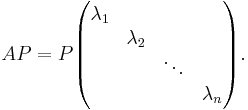
Writing P as a block matrix of its column vectors
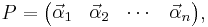
the above equation can be rewritten as
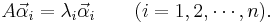
So the column vectors of P are eigenvectors of A, and the corresponding diagonal entry is the corresponding eigenvalue. The invertibility of P also suggests that the eigenvectors are linearly independent and form the basis of Fn. This is the necessary and sufficient condition for diagonalizability and the canonical approach of diagonalization.
When the matrix A is a Hermitian matrix (resp. symmetric matrix), eigenvectors of A can be chosen to form an orthonormal basis of Cn (resp. Rn). Under such circumstance P will be a unitary matrix (resp. orthogonal matrix) and P-1 equals the conjugate transpose (resp. transpose) of P.
Simultaneous diagonalization
A set of matrices are said to be simultaneously diagonalisable if there exists a single invertible matrix P such that 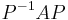 is a diagonal matrix for every A in the set. The following theorem characterises simultaneously diagonalisable matrices: A set of diagonalizable matrices commutes if and only if the set is simultaneously diagonalisable.[2]
is a diagonal matrix for every A in the set. The following theorem characterises simultaneously diagonalisable matrices: A set of diagonalizable matrices commutes if and only if the set is simultaneously diagonalisable.[2]
The set of all n-by-n diagonalisable matrices (over C) with n > 1 is not simultaneously diagonalisable. For instance, the matrices
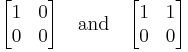
are diagonalizable but not simultaneously diagonalizable because they do not commute.
A set consists of commuting normal matrices if and only if it is simultaneously diagonalisable by a unitary matrix; that is, there exists a unitary matrix U such that 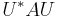 is diagonal for every A in the set.
is diagonal for every A in the set.
In the language of Lie theory, a set of simultaneously diagonalisable matrices generate a toral Lie algebra.
Examples
Diagonalizable matrices
- Involutions are diagonalisable over the reals (and indeed any field of characteristic not 2), with 1's and -1's on the diagonal
- Finite order endomorphisms are diagonalisable over the complex numbers (or any algebraically closed field where the characteristic of the field does not divide the order of the endomorphism) with roots of unity on the diagonal. This follows since the minimal polynomial is separable, because the roots of unity are distinct.
- Projections are diagonalizable, with 0's and 1's on the diagonal.
- Real symmetric matrices are diagonalizable by orthogonal matrices; i.e., given a real symmetric matrix
 ,
, 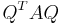 is diagonal for some orthogonal matrix
is diagonal for some orthogonal matrix 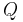 . More generally, matrices are diagonalizable by unitary matrices if and only if they are normal. In the case of the real symmetric matrix, we see that
. More generally, matrices are diagonalizable by unitary matrices if and only if they are normal. In the case of the real symmetric matrix, we see that 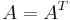 , so clearly
, so clearly 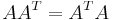 holds. Examples of normal matrices are real symmetric (or skew-symmetric) matrices (e.g. covariance matrices) and Hermitian matrices (or skew-Hermitian matrices). See spectral theorems for generalizations to infinite-dimensional vector spaces.
holds. Examples of normal matrices are real symmetric (or skew-symmetric) matrices (e.g. covariance matrices) and Hermitian matrices (or skew-Hermitian matrices). See spectral theorems for generalizations to infinite-dimensional vector spaces.
Matrices that are not diagonalizable
Some matrices are not diagonalizable over any field, most notably nonzero nilpotent matrices. This happens more generally if the algebraic and geometric multiplicities of an eigenvalue do not coincide. For instance, consider
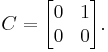
This matrix is not diagonalizable: there is no matrix U such that 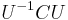 is a diagonal matrix. Indeed, C has one eigenvalue (namely zero) and this eigenvalue has algebraic multiplicity 2 and geometric multiplicity 1.
is a diagonal matrix. Indeed, C has one eigenvalue (namely zero) and this eigenvalue has algebraic multiplicity 2 and geometric multiplicity 1.
Some real matrices are not diagonalizable over the reals. Consider for instance the matrix
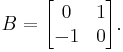
The matrix B does not have any real eigenvalues, so there is no real matrix Q such that 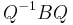 is a diagonal matrix. However, we can diagonalize B if we allow complex numbers. Indeed, if we take
is a diagonal matrix. However, we can diagonalize B if we allow complex numbers. Indeed, if we take
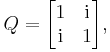
then is diagonal.
Note that the above examples show that the sum of diagonalizable matrices need not be diagonalizable.
How to diagonalize a matrix
Consider a matrix
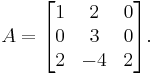
This matrix has eigenvalues
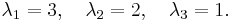
So A is a 3-by-3 matrix with 3 different eigenvalues, therefore it is diagonalizable. Note that if there are exactly n distinct eigenvalues in an n×n matrix then this matrix is diagonalizable.
These eigenvalues are the values that will appear in the diagonalized form of matrix , so by finding the eigenvalues of we have diagonalized it. We could stop here, but it is a good check to use the eigenvectors to diagonalize .
The eigenvectors of A are
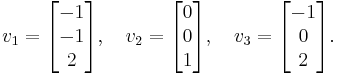
One can easily check that 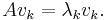
Now, let P be the matrix with these eigenvectors as its columns:
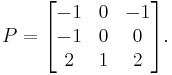
Note there is no preferred order of the eigenvectors in P; changing the order of the eigenvectors in P just changes the order of the eigenvalues in the diagonalized form of A. [3]
Then P diagonalizes A, as a simple computation confirms:
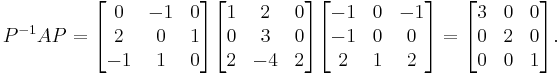
Note that the eigenvalues 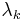 appear in the diagonal matrix.
appear in the diagonal matrix.
Alternative Method
Starting with: 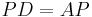 , where
, where ![P = [\vec{p_1}, \vec{p_2}]](/2012-wikipedia_en_all_nopic_01_2012/I/daf86083c762d1955d9dd3c20d1216e6.png) , and the Diagonalization matrix
, and the Diagonalization matrix 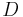 is:
is:
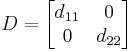
Distribute into the column vectors of 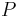 .
.
![PD = [A\vec{p_1},A\vec{p_2}]](/2012-wikipedia_en_all_nopic_01_2012/I/684a91271db57c571732823c392998f8.png)
Then can be broken down to its column vectors as follows:
![P[d_{11}\vec{e_1},d_{22}\vec{e_2}] = [A\vec{p_1},A\vec{p_2}]](/2012-wikipedia_en_all_nopic_01_2012/I/147d8c54840b7aef7c3cf73e61f68902.png)
Multiplying on the left side of the equation gives:
![[\vec{d_{11}}\vec{p_1}, \vec{d_{22}}\vec{p_2}] = [A\vec{p_1},A\vec{p_2}]](/2012-wikipedia_en_all_nopic_01_2012/I/2ad69976b77a117af3866c0b70d7f7a7.png)
Setting each entry of the matrix to its corresponding entry:
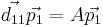
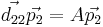
Then the equations can be solved as follows, using the same process for both:
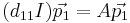
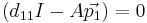
and it solves for 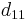 , which is the first entry in the diagonal matrix, and also the first eigenvalue.
, which is the first entry in the diagonal matrix, and also the first eigenvalue.
An application
Diagonalization can be used to compute the powers of a matrix A efficiently, provided the matrix is diagonalizable. Suppose we have found that
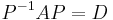
is a diagonal matrix. Then, as the matrix product is associative,
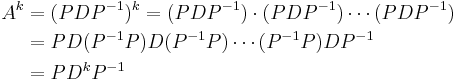
and the latter is easy to calculate since it only involves the powers of a diagonal matrix. This approach can be generalized to matrix exponential and other matrix functions since they can be defined as power series.
This is particularly useful in finding closed form expressions for terms of linear recursive sequences, such as the Fibonacci numbers.
Particular application
For example, consider the following matrix:
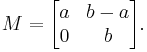
Calculating the various powers of M reveals a surprising pattern:
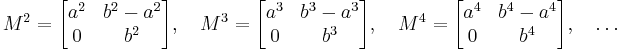
The above phenomenon can be explained by diagonalizing M. To accomplish this, we need a basis of R2 consisting of eigenvectors of M. One such eigenvector basis is given by
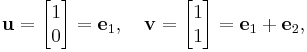
where ei denotes the standard basis of Rn. The reverse change of basis is given by
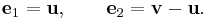
Straightforward calculations show that

Thus, a and b are the eigenvalues corresponding to u and v, respectively. By linearity of matrix multiplication, we have that

Switching back to the standard basis, we have
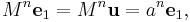
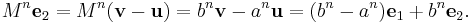
The preceding relations, expressed in matrix form, are
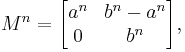
thereby explaining the above phenomenon.
Quantum mechanical application
In quantum mechanical and quantum chemical computations matrix diagonalization is one of the most frequently applied numerical processes. The basic reason is that the time-independent Schrödinger equation is an eigenvalue equation, albeit in most of the physical situations on an infinite dimensional space (a Hilbert space). A very common approximation is to truncate Hilbert space to finite dimension, after which the Schrödinger equation can be formulated as an eigenvalue problem of a real symmetric, or complex Hermitian, matrix. Formally this approximation is founded on the variational principle, valid for Hamiltonians that are bounded from below. But also first-order perturbation theory for degenerate states leads to a matrix eigenvalue problem.
See also
- Defective matrix
- Scaling (geometry)
- Triangular matrix
- Semisimple operator
- Diagonalizable group
- Jordan normal form
- Weight module – associative algebra generalization
External links
Notes
- ^ Horn & Johnson 1985
- ^ Horn & Johnson 1985, pp. 51–53
- ^ Anton, H.; Rorres, C. (22 Feb 2000). Elementary Linear Algebra (Applications Version) (8th ed.). John Wiley & Sons. ISBN 978-0471170525.
References
- Horn, Roger A.; Johnson, Charles R. (1985). Matrix Analysis. Cambridge University Press. ISBN 978-0-521-38632-6.